The press exploded last month with news of the smashing of another frontier in artificial intelligence (AI); ‘art’ created solely by computer algorithm, aka AI-generated art. Text-to-image generation tools from Stable Diffusion to DALL-E and Midjourney are now being used all over the internet to create bizarre, often beautiful, images. One piece of AI art created this way, Théâtre D’opéra Spatial, even won an art competition, upsetting artists everywhere.
These AI models enable anyone to input a text ‘prompt’ describing the kind of image or art they would like to see and, even if it’s something that has never existed before (an avocado rinding a bike for example), the models can do a pretty good job of generating a realistic image of it.
What can AI-generated art do?
Strictly for the purposes of research, I played around with two of the biggest image models, Stable Diffusion and DALL-E to find out. Starting with DALL-E my prompt of “a wire haired dachshund doing a yoga pose in the style of Vermeer, soft morning light” produced this undeniably cute and totally inoffensive image;

And a few others as variations on a theme;

I changed the prompt to substitute ‘Monet’ for ‘Vermeer’;
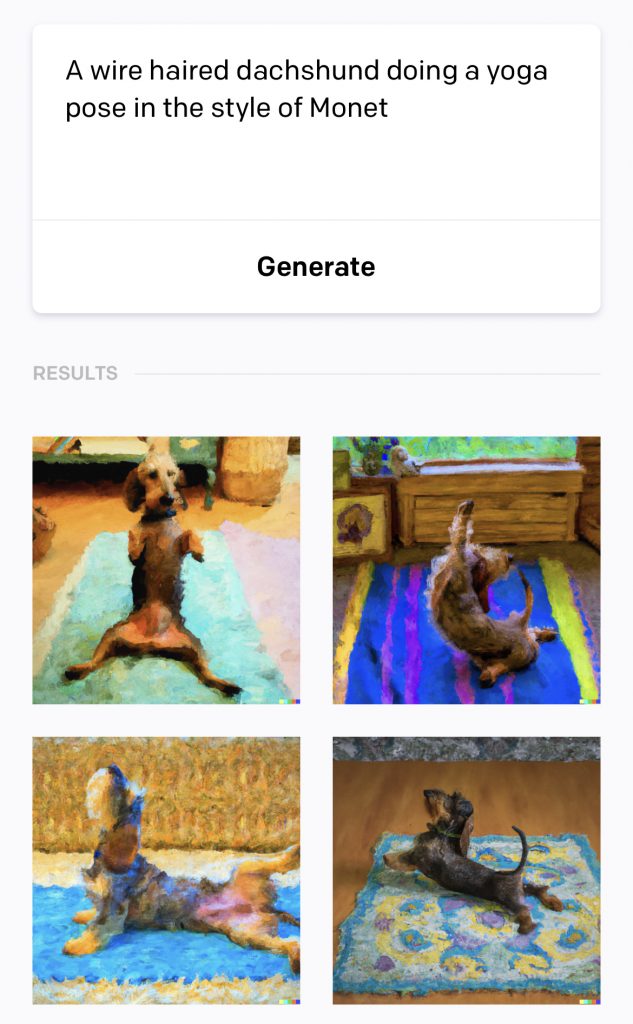
The Stable Diffusion images using an identical prompt were less appealing and didn’t seem to have completely got the ‘yoga’ memo, but were still pretty inoffensive;

How does it work?
AI-generated art isn’t magic. Like so much about the shiny new world of artificial intelligence its capabilities may look miraculous but the output is the product of a quite a laborious, often human-intensive, process.
AI text-to-image models are trained on millions of images – lifted from those which already exist on the internet – together with their associated text captions. Each model ‘learns’ ideas from these images, exactly like a child learns to read and associate pictures of objects with their words. If the AI has seen plenty of photos of people doing yoga, it will work out that it involves distinctive poses. If you show it dachshunds, it will understand those dogs have long bodies, short legs and certain features. Once those concepts are understood, you can ask it to generate an image of “a dachshund doing yoga” and it can do it, even if an image has never existed before. Similarly, if it’s seen photos of work by artists, such as Vermeer or Monet, it learns what brushwork, hues and tones characterise those artists and can then overlay that artist’s style on any of its generated images.
What are the problems with AI-generated art?
Quite apart from the many living artists who are upset that text-to-image models are being trained on their work, and then producing new work in their style that they have no copyright over, there is a much bigger problem of bias and problematic content. The models are only ever as good as the images and description input into them, so those images and their descriptions (scraped from the internet and labelled by, well, just internet users), may reproduce quite a lot that’s wrong with our real world in this ‘new’ world of AI-generated art.
“these models were trained on image-text pairs from a broad internet scrape, the model may reproduce some societal biases and produce unsafe content.”
Stable Diffusion website
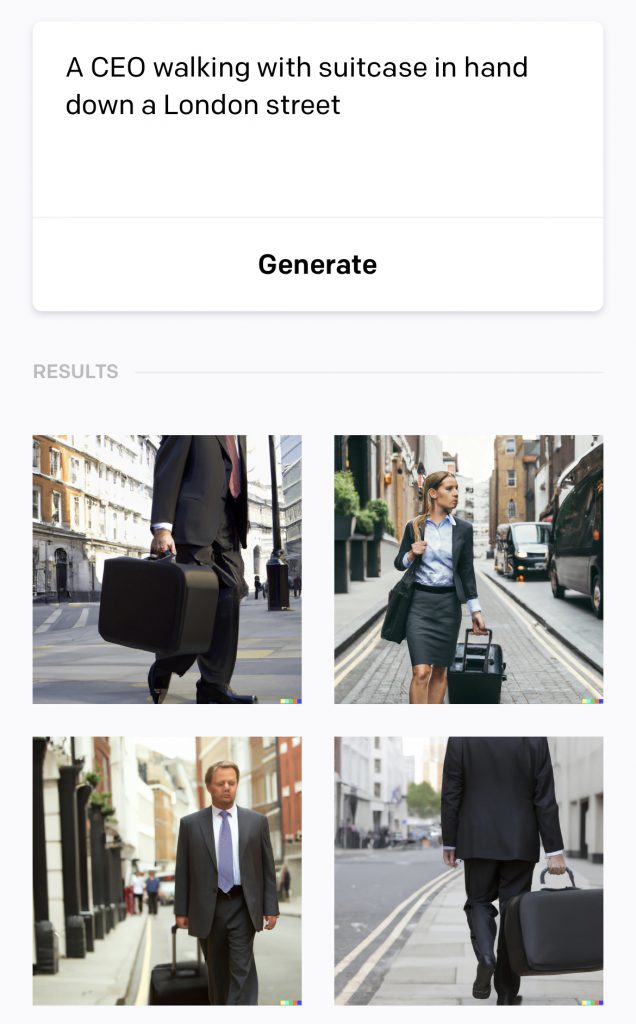
You can see what I mean when you look at the results from the prompt I put into Stable Diffusion of “a CEO, walking with suitcase in hand down a London street”;

You may not have immediately spotted that all the images are men and, although they are a bit blurred, look almost certainly white.
DALL-E does a bit better with this prompt and at least includes one woman, but still no people of colour.
AI can be racist, misogynistic and offensive, just like people are
Although the tools’ creators have mostly worked hard to prevent the generation of images involving nudity or violence, or images using public figures, there are still much more problematic and offensive images that can be generated using relatively mundane prompts, which I won’t reproduce here. And there’s a big problem of the potential for AI-generated art to be used for disinformation and misinformation as images of real-world events that have never taken place can now be easily created and spread.
Which all begs the question – why have these tools been created and released for public use if so much about their design and application is a problem? Meta’s Chief AI Scientist put the onus firmly on ‘society at large’ (whatever, and whoever, that is), to decide what to do with them last week, in an attempt to absolve Big Tech from any responsibility from AI misuse.
Whatever ‘society at large’ decides, these tools are already with us and history, both recent and far, shows that they probably won’t just be used to produce cute pictures of dachshunds doing yoga but images with altogether more disruptive and sinister motives. Good luck to us all navigating our way through this.

For more about keeping safe in the online world, including dealing with misinformation and ‘fake news’ – pick up a copy of my new book.